Clastro
An interstellar objects sorter
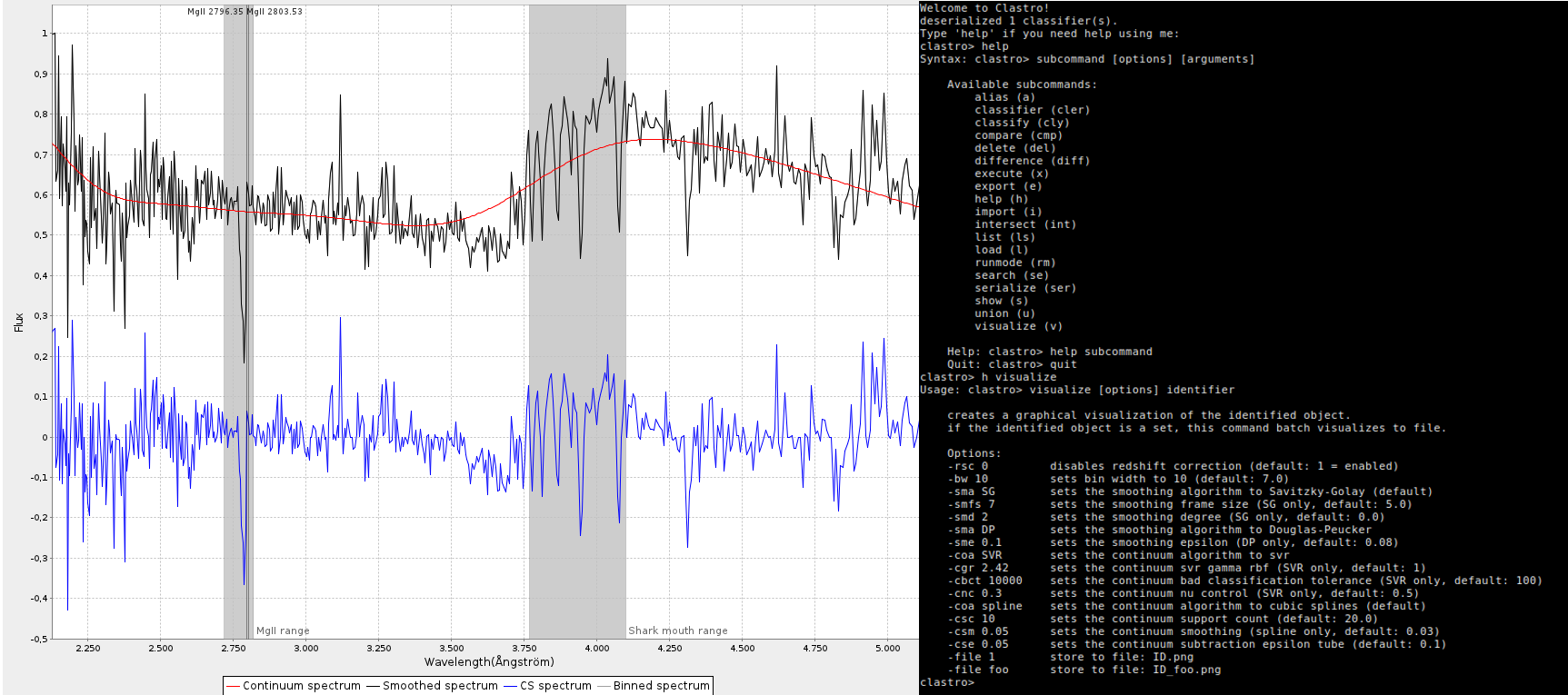
Clastro is an automatic sorter of interstellar objects from the Sloan Digital Sky Survey DB using machine learning algorithms.
Part command line, part GUI program, it aids astronomers on the inspection and catalogation of huge amounts of data from the telescopes, in this case from the SDSS catalog (30TB of spectroscopic and photometric data). The program reads raw spectra data, spectra information, photometric information, redshift values, etc, and builds trained classifiers. Those classifiers can use a list of features to classify unknown interstellar objects into quasars or galaxies.
The program uses several algorithms. For feature extraction and transformations:
- Douglas-Peucker algorithm or Savitzky Golay filter for smoothing the curves
- Cubic Spline interpolation or Support Vector Regression for the continuum extraction
For classification:
- Support Vector Machines
- K-Nearest Neighbour
Role
Java software developer in a team of 4 at Westfälische Wilhelms-Universität Münster.
Features
- Fast connection to the SDSS database and complex search queries
- Private object cache
- Lazy calculation method of all the needed data for the feature extraction
- Key algorithms for feature extraction and data preparation
- Machine learning algorithms to classify objects by their features
- Cross validation algorithm has been used to evaluate our classifiers and estimate how accurately they work
- Import & export features for set of data and single interstellar objects
- Modular design
- Test Driven Development
Repository
Removed by request of M. Westermeier.
Technologies used
Java, SQL, JTest, Scrumm.